
Something shifted in AI last month — and if you blinked, you might have missed it. OpenAI’s GPT-5.4, released on March 5, 2026, didn’t just set a new benchmark record. It crossed a threshold that AI researchers and economists have debated for years: the point at which a model can perform the equivalent of a human professional’s work across a wide range of white-collar jobs. With an 83% score on the GDPVal benchmark — matching or exceeding industry professionals in 83 out of every 100 comparisons — the conversation about AI in the workplace is no longer hypothetical. It’s happening now.
But GPT-5.4 isn’t just about one number. It’s the first frontier model to credibly handle coding, complex reasoning, and full computer use in a single package. That trifecta has profound implications for developers, businesses, and every knowledge worker trying to understand what their job looks like in 2027. Let’s break down exactly what GPT-5.4 can do — and what it means for the world of work.
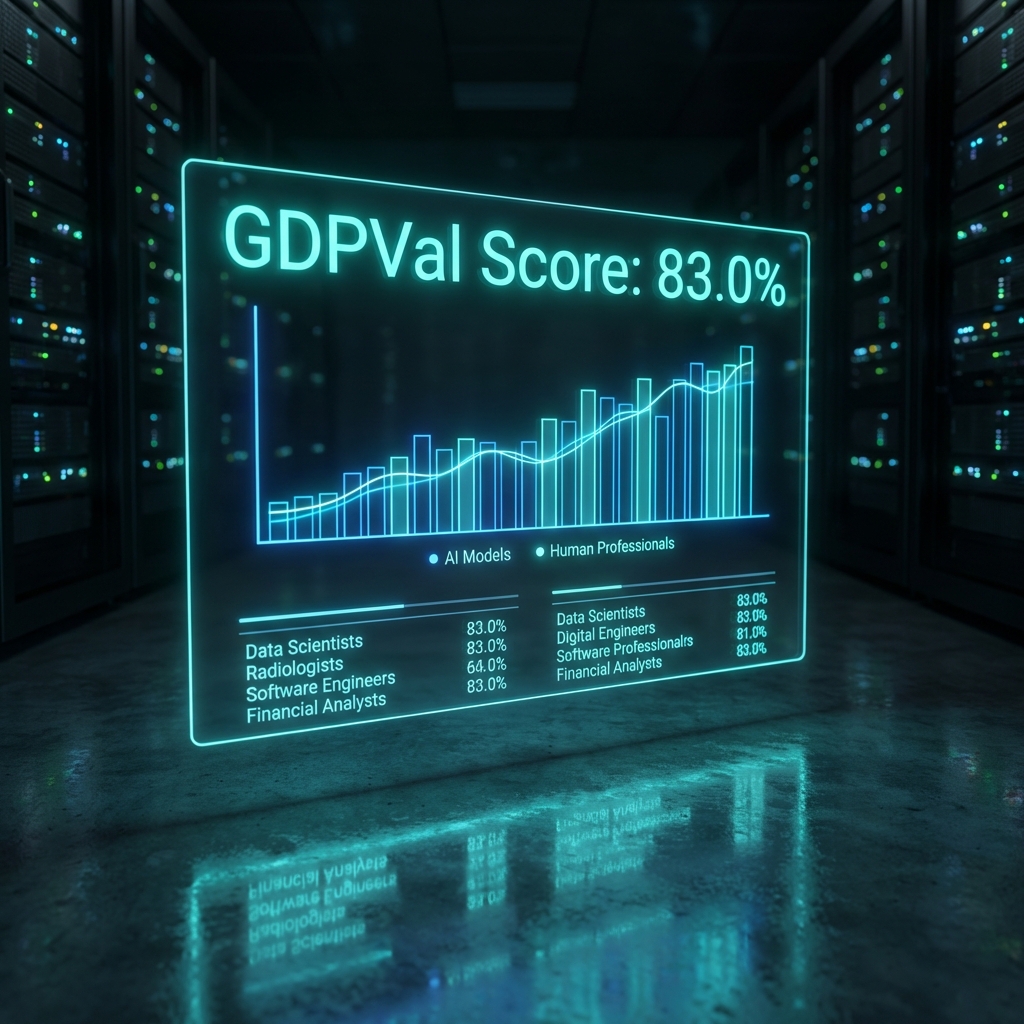
What Is GDPVal and Why Does 83% Change Everything?
GDPVal — short for Gross Domestic Product Value benchmark — is one of the most rigorous tests of AI work quality ever designed. Rather than testing on academic math or coding puzzles, GDPVal asks models to complete real knowledge work tasks across 44 distinct white-collar occupations. We’re talking about generating sales presentations, filling out accounting spreadsheets, building manufacturing process diagrams, drafting urgent care schedules, producing short professional videos, and dozens of other tasks pulled directly from real jobs.
The scoring method is deliberately harsh. Human professionals in each occupation judge the outputs blindly — they don’t know whether a human or an AI made the submission. A model “wins” a comparison only when an expert judge rates its output as good as or better than a professional’s first attempt at the same task. GPT-5.2, OpenAI’s previous flagship model, won 70.9% of those comparisons — already an impressive figure. GPT-5.4 leaped to 83.0%.
To put that in perspective: GPT-5.4 produces work that professional judges rate as at least as good as a human colleague’s output in four out of every five tasks, across nearly four dozen career fields. Previous AI models improved benchmark scores incrementally. This 12-point jump in a single generation is the kind of gain that forces companies, policymakers, and workers to sit up and seriously reconsider their planning horizons.
What makes this particularly striking is that GDPVal doesn’t test isolated micro-tasks. Each prompt asks for a complete, usable work product — the kind of deliverable a manager would actually request from an employee. That’s the bar GPT-5.4 is now clearing, repeatedly, across an extraordinarily wide range of professions.
Three Powerhouses in One: Coding, Reasoning, and Computer Use United
One of the most underreported aspects of GPT-5.4 is what it represents architecturally. For the past two years, OpenAI has maintained separate, specialized models for different capability classes. You had coding-focused models, reasoning-heavy “o-series” models with extended chain-of-thought, and early computer-use models still marked as experimental. GPT-5.4 collapses all of these into a single unified model.
This isn’t just a convenience improvement. It means that a single API call can now handle a complex multi-step task that previously would have required multiple specialized models, extensive prompt engineering, and careful orchestration. A developer building an AI agent no longer has to decide whether a given subtask requires the “coding model” or the “reasoning model” — GPT-5.4 handles the full stack.
The Pro variant’s performance on ARC-AGI-2 reinforces just how serious this reasoning upgrade is. ARC-AGI-2 is widely considered the hardest publicly available test of abstract reasoning and generalization — the kind of puzzle-solving that requires genuine pattern recognition rather than memorization. GPT-5.4 Pro scored 83.3%, compared to just 54.2% from the previous generation. That 29-point improvement on abstract reasoning, achieved simultaneously with the GDPVal gains, suggests these aren’t separate capability wins — they’re the result of a fundamentally improved reasoning architecture that generalizes across task types.

Computer Use Gets Real: GPT-5.4 Beats Humans at Screen Navigation
Computer use has been the most ambitious — and most frustrating — frontier in AI capability. The promise is obvious: give an AI model the ability to see your screen, move the mouse, click buttons, and type in applications, and you have an autonomous digital worker. The reality, until recently, has been a series of impressive demos followed by fragile real-world performance.
GPT-5.4 changes that calculus. On the OSWorld Verified benchmark — an industry-standard test of autonomous desktop navigation across real software applications — GPT-5.4 scored 75.0% success rate. Human professionals completing the same tasks scored 72.4%. This is the first time a general AI model has surpassed human performance on this benchmark, and it’s not a marginal win.
What makes this meaningful in practice is the self-verification loop that comes with computer use. In live demonstrations, GPT-5.4 generated interactive data visualizations, immediately reviewed them on-screen, identified errors in its own initial outputs, and refined them — all without human prompting. That closed feedback loop — see, evaluate, correct — is exactly what was missing from earlier computer-use models. Most previous attempts could navigate screens in controlled conditions but couldn’t reliably catch and fix their own mistakes.
This capability has immediate implications for anyone who relies on repetitive computer workflows: data entry, web research compilation, report formatting, cross-application copy-paste tasks. These are the kinds of workflows that are genuinely time-consuming for humans and genuinely automatable with a reliable computer-use model. GPT-5.4 appears to be the first model that crosses the reliability threshold required for real deployment.
The Tool Search Feature: How OpenAI Cut Token Costs by 47%
Buried in the GPT-5.4 release notes is a practical engineering improvement that will matter enormously to developers building on the API: Tool Search. In complex agentic applications, models are typically given access to dozens or even hundreds of tools — functions they can call to retrieve data, run code, search the web, interact with databases, and more. Until now, all of those tool definitions had to be loaded into the context window upfront, consuming thousands of tokens before the model even began processing the actual task.
Tool Search changes the architecture by dynamically retrieving only the tool definitions that are relevant to the current query. Instead of loading every possible tool at once, the model identifies which tools it needs and fetches their schemas on demand. The result is a 47% reduction in token consumption for complex multi-tool applications — a massive cost savings for production deployments at scale.
For individual API users, this translates to significantly lower per-task costs despite GPT-5.4’s higher base per-token pricing. OpenAI has argued that the net cost of completing complex tasks is lower with GPT-5.4 than with GPT-5.2, precisely because the new model accomplishes more per token while consuming fewer tokens overall through optimizations like Tool Search. Early developer testing broadly confirms this claim, though results vary considerably by use case.
The Safety Milestone Nobody Is Celebrating: High Capability Cybersecurity Rating
GPT-5.4 Thinking became the first general reasoning model to receive a “High Capability” cybersecurity rating from OpenAI’s safety evaluation team. This is not good news, and OpenAI is not celebrating it as one. A High Capability rating means the model demonstrates enhanced potential to assist with sophisticated cyberattacks compared to previous generations.
OpenAI’s response is the deployment of real-time blockers specifically designed for cybersecurity threat scenarios — guardrails that activate when the model’s outputs enter territory that could enable attacks. This is a meaningful investment in safety infrastructure, but it also reflects the broader reality of the current frontier: as models become more capable across knowledge domains, their potential for misuse grows proportionally. The same capabilities that let GPT-5.4 write better software, debug complex systems, and navigate computers autonomously also make it more powerful in adversarial hands.
This is an honest tension that OpenAI is surfacing publicly rather than quietly managing. Whether the real-time blockers are sufficient will be tested by the security research community in the weeks and months ahead.
The Fine Print: What 83% Doesn’t Mean
It’s worth being precise about what the GDPVal score does and doesn’t tell us. The benchmark tests isolated tasks — individual work products completed from a standing start. It does not test sustained job performance across a full workday, with all the context management, interpersonal communication, shifting priorities, and institutional knowledge that real professional work involves. Scoring 83% on knowledge work tasks is not the same as replacing 83% of knowledge workers.
There is also a concerning hallucination pattern in GPT-5.4 that deserves attention. When the model is wrong, it tends to express confident assertions rather than uncertainty. Unlike earlier models, which often flagged ambiguity or lack of confidence, GPT-5.4 can produce fluent, authoritative-sounding incorrect answers — what reviewers have described as “bluffing.” In high-stakes domains like medicine, law, or financial analysis, an AI that sounds certain when it’s wrong is more dangerous than one that hedges.
Performance improvements also remain uneven across benchmarks. While the GDPVal and ARC-AGI-2 gains are dramatic, some other evaluation metrics show unexpected declines from the GPT-5.2 baseline. This suggests that capability improvements are not yet uniformly robust — certain task types benefited enormously from architectural changes that others did not.
What This Means for Knowledge Workers and the Future of Work
The honest answer is that GPT-5.4’s GDPVal milestone accelerates a timeline that was already in motion. The 83% score does not mean AI is doing 83% of office work today. It means that for specific, well-defined knowledge work tasks, AI has crossed the human-performance threshold in a test environment. Real workplace deployment requires reliability at scale, seamless integration with existing systems, accountability structures, and — crucially — enough organizational trust to actually delegate meaningful work to AI systems.
What GPT-5.4 does is remove the performance argument as the primary reason not to deploy AI for knowledge work. Previous model limitations gave organizations an easy out: AI isn’t good enough yet. For an increasing range of well-defined tasks across a growing list of professions, that argument no longer holds. The conversation is shifting from “can AI do this?” to “how do we safely integrate AI that can?”
For knowledge workers themselves, the most valuable skill in this environment is not one that GPT-5.4 is competing for: the ability to correctly evaluate AI output, catch the confident hallucinations, identify the edge cases where current models still fall short, and combine AI capability with genuine domain expertise. The people who thrive in the next phase of AI adoption will be those who understand precisely what the model can and cannot be trusted to do — and build their workflows accordingly.
GPT-5.4 is not the end of knowledge work. But it is, demonstrably, a new beginning for what AI-assisted work looks like. The 83% number is going to be cited for a long time.





Leave a Reply